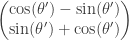Projecteurs, symétrie et rotation :
Projecteurs :
Nous entamons ici l’avant dernier point sur les espaces vectoriels. Vous remarquerez que nous ne citons presque plus les mots espace vectoriel, car ce serait une assertion évidente que de préciser que nous travaillons dans ces structures.
Nous allons voir maintenant ce que ce sont : Des projecteurs, la symétrie, et la rotation.
Que pourrions nous voir, intuitivement, lorsqu’on évoque ces trois notions ?
Commençons par la projection.
Tout d’abord, précisons qu’il s’agit bien évidemment de vecteurs. Expliquons intuitivement et schématiquement de quoi il s’agit, et ensuite, nous verrons la définition et les propriétés formelles de cette dernière.
Prenons deux espaces 
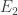
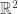
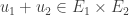

Qu’est ce qu’une projection ? Voici comment nous pourrions la définir sur ce graphe :

Un projecteur n’est rien d’autre qu’une application linéaire. Cette dernière possède en particulier une propriété intéressante. Tout d’abord, voyons la définition formelle :
Soit 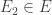
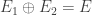


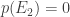




Ce que fait le projecteur, c’est qu’il annule la composante du vecteur de
En fait, on voit très bien à quoi cela correspond graphiquement. On projette, par rapport à l’axe des abscisses, le vecteur, et cela induit nécessairement qu’il se retrouve dans
Démontrons maintenant qu’il s’agit bien d’une application linéaire, et même plus précisément, d’un endomorphisme idempotent (Nous verrons en détails ce que c’est).
Prenons 

Si on fait la somme des deux projections de ces deux vecteurs, on a :
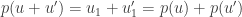
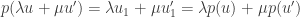
On peut tirer quelques propriétés intéressantes de cette application de projection :

C’est très facile à démontrer. On sait que 


Cette notion se généralise évidemment à 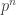
En fait cette propriété est une implication réciproque, autrement dit, si 
La seconde propriété, est que 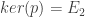

On voit bien que, la seule projection qui donne le vecteur nul, est la projection d’un vecteur de
On sait que le noyau d’une application linéaire, c’est un sous ensemble de l’espace de départ qui a pour image, le vecteur nul dans l’espace d’arrivée, or, si 


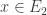

Attention, il faut bien préciser qu’avant la projection, on prend un 

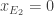

Une autre propriété concernant l’image maintenant :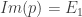

Tout d’abord, montrons que 
Prenons un 

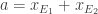

Or, 
Maintenant, montrons que 
Soit 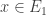

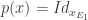

Il y a d’autres façon de définir le noyau et l’image. En fait, on a jusqu’à présent défini le projecteur 



Quelles sont donc les propriétés qui pourraient découler de ceci ?
On voit bien que 


On pose 
Cette application est bien un projecteur, et il est le projecteur de
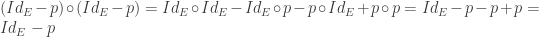
Voici ce que l’on peut affirmer, et que l’on va démontrer :
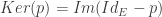
Tout d’abord, pourquoi est-ce que 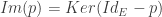
Eh bien, on sait que 

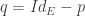
En fait, on peut aisément se représenter ceci graphiquement. En effet, on sait que l’image de
A présent, on peut voir très rapidement la seconde égalité, en effet :
On sait que 
Ceci est en réalité exactement la même chose que pour l’image de
CQFD.
On peut voir les choses autrement…
Une autre façon de voir les choses, est de poser 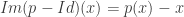
On a donc 
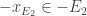



Prenons un exemple un peu velu, mais qui vous permettra de bien comprendre le raisonnement général:
Soit E, un 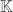
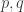

On considère un troisième application linéaire 

La première question que nous allons nous poser, est de savoir si 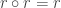
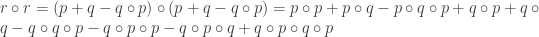

Donc
Attention,

Ensuite, on veut montrer que 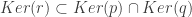
On va encore procéder à méthode de double inclusion.
Prenons un 
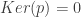

Donc :
Or, 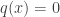
Mais donc, 
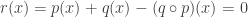


Maintenant, prouvons l’inclusion réciproque.
Soit 
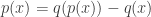
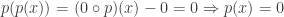
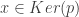



Par conséquent,
On peut donc conclure par la double inclusion que

A présent, vérifions que 

Tout d’abord, prenons 

On voit clairement que 
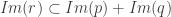
L’inclusion réciproque maintenant.
Pour montrer que 
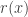
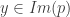


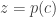
On a également 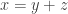

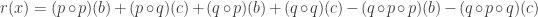

Que voit-on ? On sait que 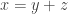
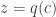




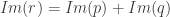
Il nous reste à montrer que 
Pour cela, il faut montrer que
Prenons de nouveau un 

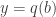


Maintenant, si on applique le projecteur 
En conclusion, on bien que 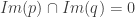

Symétrie :
Le terme symétrie devrait vous rappeler vos années à l’école primaire ou collège, en effet, ce que nous allons voir maintenant, est une vision algébrique, vectorielle, de ce qu’est une symétrie.
Tout d’abord, prenons un exemple graphique très simple d’une symétrie, et essayons de voir quelles propriétés nous pouvons en tirer :

Que vaut 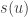

On voit clairement que prendre la symétrie de


On dit que l’application symétrique est involutive, ceci veut dire que composer deux fois un vecteur avec cette application renvoie le vecteur lui même.
Autrement dit, 
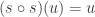

Montrons le :
Soit 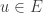
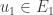


On peut facilement se représenter ceci graphiquement. En effet, en prenant une fois le symétrique de


Essayons à présent de dégager les propriétés concernant le noyau et l’image.
On sait que 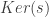
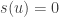
Or, on 

Vous devriez remarquer quelque chose. Nous ne l’avons pas précisé au début, mais 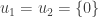

Qu’en est-il de l’image ? si on s’en réfère au théorème du rang, l’image devrait être
On sait que 
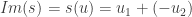
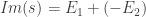

Il y a une autre façon de définir 

Donc, 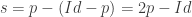
Finissons de voir les propriétés importantes des symétries en voyant les éléments invariants…
Qu’est ce qu’un élément invariant ? C’est un élément qui ne subit pas la transformation, qui reste inchangé après l’application, autrement dit, de la forme 
On pose donc 
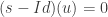
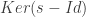
Encore une fois, on sait que 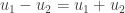
On peut donc, pour les raisons juste au dessus, écrire 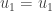



On peut donc conclure que l’ensemble des éléments invariants

Qu’en est-il de l’ensemble des éléments opposés ? Les éléments qui, lorsqu’on applique le symétrique, renvoient le vecteur 
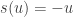
C’est très simple, il suffit de poser :


Or, on peut calculer 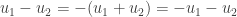
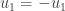

Par conséquent, 

On remarque immédiatement que
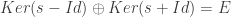
Rotation :
Penchons-nous sur un dernier exemple d’application linéaire usuelle et très importante, la rotation.
Avant de définir ce dont on parle, voyons à quoi ressemble une rotation dans le plan :

Plaçons nous dans 

On sait que le vecteur 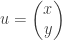
On connait l’écriture d’un vecteur à travers ses coordonnées polaires :

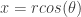

Par conséquent, l’application « 

Donc, on peut écrire la rotation de
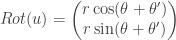
Vous voyez ce qui est possible de faire ? Il faut faire preuve d’astuce… Avant de lire la suite, réfléchissez à la simplification de cette expression.
Il faut se rappeler d’une propriété vue dans le chapitre des fonctions trigonométriques, en effet, nous allons nous servir de la formule de 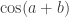

![Rot(u)=\begin{pmatrix} r [\cos(\theta)\cos(\theta')]- (\sin(\theta)\sin(\theta')] \\ r [\sin(\theta)\cos(\theta')]+ r[ (\sin(\theta')\cos(\theta)] \end{pmatrix}](https://s0.wp.com/latex.php?latex=Rot%28u%29%3D%5Cbegin%7Bpmatrix%7D+r+%5B%5Ccos%28%5Ctheta%29%5Ccos%28%5Ctheta%27%29%5D-+%28%5Csin%28%5Ctheta%29%5Csin%28%5Ctheta%27%29%5D++%5C%5C++++r+%5B%5Csin%28%5Ctheta%29%5Ccos%28%5Ctheta%27%29%5D%2B+r%5B+%28%5Csin%28%5Ctheta%27%29%5Ccos%28%5Ctheta%29%5D+++%5Cend%7Bpmatrix%7D&bg=ffffff&fg=333333&s=0&c=20201002)
On distribue :
![Rot(u)=\begin{pmatrix} r \cos(\theta)\cos(\theta')]- r\sin(\theta)\sin(\theta') \\ r \sin(\theta)\cos(\theta')+ r(\sin(\theta')\cos(\theta) \end{pmatrix}](https://s0.wp.com/latex.php?latex=Rot%28u%29%3D%5Cbegin%7Bpmatrix%7D+r+%5Ccos%28%5Ctheta%29%5Ccos%28%5Ctheta%27%29%5D-+r%5Csin%28%5Ctheta%29%5Csin%28%5Ctheta%27%29+%5C%5C+r+%5Csin%28%5Ctheta%29%5Ccos%28%5Ctheta%27%29%2B+r%28%5Csin%28%5Ctheta%27%29%5Ccos%28%5Ctheta%29+%5Cend%7Bpmatrix%7D&bg=ffffff&fg=333333&s=0&c=20201002)
On voit qu’on peut remplacer des valeurs par

Nous n’avons pas encore vu les matrices d’application linéaire, mais nous avons nul besoin de les définir pour affirmer que l’application de la rotation vectorielle est linéaire, est un endomorphisme, et se définie comme ceci :